
Diffusion Models, Part I
A Very Gentle Introduction

Hi everyone, Mark here!
Welcome to our first adventure in "The Visual Computing"! Today, we’re kicking off a series on diffusion models. If you've been orbiting this planet for the last few years, you’ve probably heard the buzz. If not, don’t worry — I’ve got you covered!
🚀 Unlock the Future of Technology with Free Access! 🚀
Join our community and dive into the exciting world of Computer Vision. Don't miss out on exclusive content — all for FREE! 📩
What You’ll Learn
To get the most out of this article, you just need a basic understanding of machine learning and neural networks. By the end, you’ll be able to confidently answer:
What are generative models?
What are diffusion models?
How do diffusion models work?
Generative Models
Machine learning models can be broadly categorized based on the problems they solve. Today, we’ll focus on generative models, but let's first distinguish them from discriminative models.
Discriminative models are the go-to for tasks like image classification and object detection — where you’re drawing conclusions from data. Generative models, on the other hand, are all about creating new data from existing input.

Imagine generative models as artists, creating new and original works, while discriminative models are more like art critics, analyzing and judging existing pieces.

Though generative models have been around for a while, they’ve recently surged in popularity thanks to tools like ChatGPT, DALL-E, and Midjourney (which is powered by a diffusion model).
The diffusion model is a type of generative model. Just a heads-up: there's some really cool stuff happening right now. People are starting to use diffusion models for problems that usually call for discriminative models. We'll dive into these exciting developments in upcoming newsletters!
Principles of Diffusion Models
The term "diffusion" comes from the physical theory of non-equilibrium thermodynamics. In this type of system, unlike systems in equilibrium, macroscopic variables — such as pressure and temperature — change over time. Think of spraying perfume — it starts concentrated at one point and then disperses. Reversing this process to gather the perfume back into the bottle is physically impossible.
In deep diffusion models, data undergoes iterative transformations where noise is gradually introduced, simulating a diffusion-like process. Then, we train a model to reverse this process, effectively learning how to transform noise back into meaningful data. It’s like teaching a computer to un-spray the perfume!
As the authors themselves describe it as:
"The essential idea, inspired by non-equilibrium statistical physics, is to systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process. We then learn a reverse diffusion process that restores structure in data, yielding a highly flexible and tractable generative model of the data.", Sohl-Dickstein et al., 2015.
The diffusion process, done iteratively, can be seen as a Markov Chain, meaning that each state depends only on the previous one. This ensures that we don’t carry long dependencies across iterations.

Typically, this type of model is explained for image generation, so we're gonna do the same to break down the two main steps: forward diffusion and reverse diffusion. Essentially, we start by adding some noise to the data (forward diffusion), and then we train the network to clean it up (reverse diffusion). It's important to note that our model isn't the one causing the noise; it's simply taught to fix it.
Forward Diffusion
In the forward diffusion process, we add noise to data iteratively. Imagine starting with a clear image. At each step, we add a bit more noise, gradually transforming the image until it becomes unrecognizable.

Reverse Diffusion
In the reverse diffusion process, our model is trained to predict all the noise to recreate the original image from a noisy input. During inference, it predicts the noise to be removed, but we only remove a fraction of it at each iteration. This process is repeated until we achieve the final “noise-free” image.

You may have noticed (or maybe not lol) that the output image depends on the input noise, such that changing the noise will produce different outputs. In this way, we have a model that can generate new data based on random noise.
Here are some brief responses to potential questions you might doing to yourself now:
Why is forward diffusion iterative? A: It allows training on various noise levels, although, in practice, we may not exactly follow this approach.
Why remove a fraction of the noise instead of performing inference in a single step? A: Removing all noise at once (or generating a high-quality image directly from noise) is exceptionally challenging and often results in poor quality. However, reducing a little bit of its noise is more feasible.
What's the main drawback of these methods? A: They can be slow due to the necessity for numerous iterations.
Text-Guided Reverse Diffusion
The essence of the original diffusion model operates as described. Yet, it's crucial to underscore a notable feature of contemporary models. Text-guided reverse diffusion introduces an additional element within each iteration: a textual prompt to guide the image generation process. It allows the model to incorporate textual input alongside the image generation process, providing more structured outcomes beyond simple randomness.
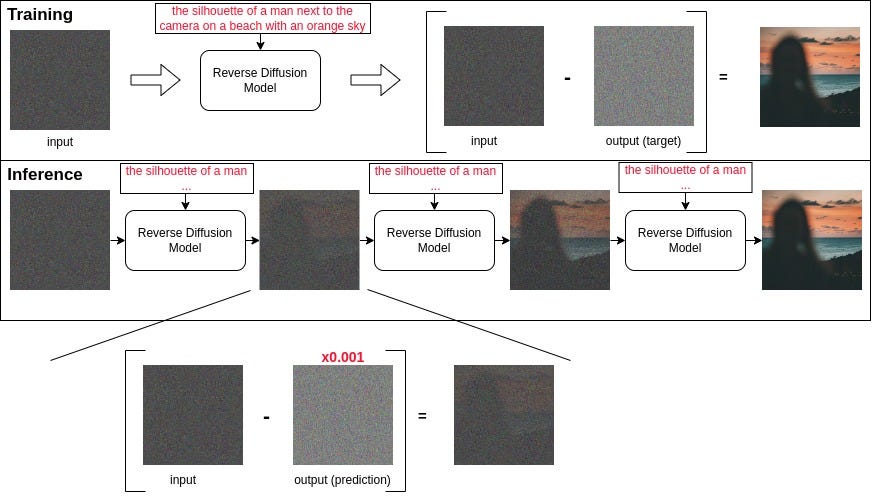
The output image is conditioned by the input text, meaning that the model aims to generate images that correspond to the description provided by the input text.
Why Are Diffusion Models So Popular?
Simply put, diffusion models generate high-quality, diverse images. Their results are impressive, making them the darlings of the generative model world. Integrating textual (or other info) input to guide the reverse diffusion process adds an extra layer of control, allowing for more precise and desired outcomes.

Conclusions
Thank you for joining me on this first leg of our journey into diffusion models! At "The Visual Computing", we aim to keep things short, sweet, and digestible. We’ll start simple and dive deeper as we go.
To grow our community, I need your active participation. Leave your comments below—tell me what you liked, what could be improved, and what topics you want to explore. Your feedback is invaluable!
Here’s a quick recap:
What are generative models? A: Models that create new data.
What are diffusion models? A: Generative models that compute data from noise.
How do diffusion models work? A: It uses a deep learning model to remove noise little by little, possibly guided by textual input.
What’s Next?
Depending on your interest, we might cover:
Deeper and mathematical explanations
Results achieved with diffusion models so far
A guide on How to Train Your
DragonDiffusion ModelExploring the architecture behind diffusion models
Some applications for diffusion models
Help me decide!
Stay tuned for more…
… and remember, signing up is free and guarantees you’ll never miss an update. Until next time, keep exploring and stay young!
See ya!